

Khoa học dữ liệu - Chuẩn bị dữ liệu
Trước khi phân tích dữ liệu, Nhà khoa học dữ liệu phải trích xuất dữ liệu và làm cho dữ liệu trở nên rõ ràng và có giá trị.
Trích xuất và đọc dữ liệu với Pandas
Trước khi dữ liệu có thể được phân tích, nó phải được nhập/trích xuất.
Trong ví dụ bên dưới, chúng tôi chỉ cho bạn cách nhập dữ liệu bằng Pandas trong Python.
Chúng tôi sử dụng hàm read_csv() để nhập tệp CSV có dữ liệu sức khỏe:
Ví dụ
import pandas as pd
health_data = pd.read_csv("data.csv", header=0, sep=",")
print(health_data) Hãy tự mình thử »Ví dụ giải thích
- Nhập thư viện Pandas
- Đặt tên khung dữ liệu là
health_data. -
header=0có nghĩa là tiêu đề cho tên biến sẽ được tìm thấy ở hàng đầu tiên (lưu ý rằng 0 có nghĩa là hàng đầu tiên trong Python) -
sep=","có nghĩa là "," được sử dụng làm dấu phân cách giữa các giá trị. Điều này là do chúng tôi đang sử dụng loại tệp .csv (các giá trị được phân tách bằng dấu phẩy)
Mẹo: Nếu có tệp CSV lớn, bạn có thể sử dụng hàm head() để chỉ hiển thị 5 hàng trên cùng:
Ví dụ
import pandas as pd
health_data = pd.read_csv("data.csv", header=0, sep=",")
print(health_data.head()) Hãy tự mình thử »Làm sạch dữ liệu
Nhìn vào dữ liệu đã nhập. Như bạn có thể thấy, dữ liệu "bẩn" với các giá trị sai hoặc chưa được đăng ký:
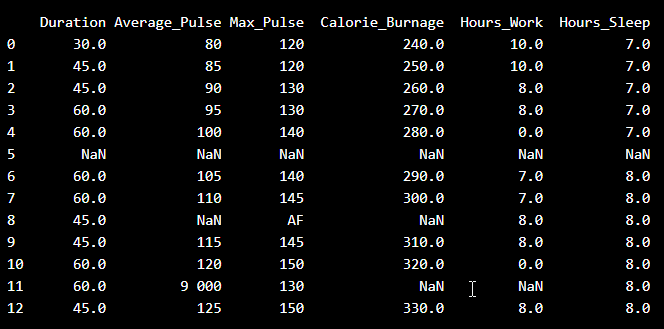
- Có một số trường trống
- Không thể có xung trung bình 9 000
- 9 000 sẽ được coi là không phải số vì có dấu cách
- Một quan sát xung tối đa được ký hiệu là "AF", điều này không có ý nghĩa
Vì vậy, chúng ta phải làm sạch dữ liệu để thực hiện phân tích.
Xóa hàng trống
Chúng tôi thấy rằng các giá trị không phải là số (9 000 và AF) nằm trong cùng một hàng với các giá trị bị thiếu.
Giải pháp: Chúng tôi có thể xóa các hàng bị thiếu quan sát để khắc phục sự cố này.
Khi chúng tôi tải tập dữ liệu bằng Pandas, tất cả các ô trống sẽ tự động được chuyển đổi thành giá trị "NaN".
Vì vậy, việc loại bỏ các ô NaN mang lại cho chúng ta một tập dữ liệu sạch có thể phân tích được.
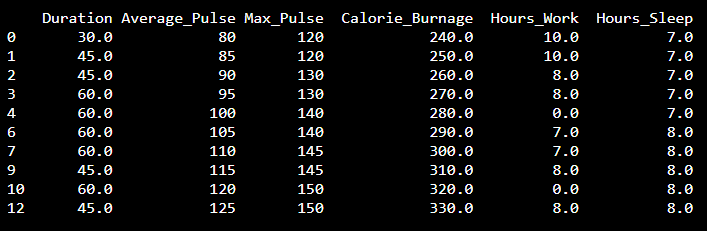
Chúng ta có thể sử dụng hàm dropna() để loại bỏ NaN. axis=0 có nghĩa là chúng tôi muốn xóa tất cả các hàng có giá trị NaN:
Kết quả là một tập dữ liệu không có hàng NaN:
Danh mục dữ liệu
Để phân tích dữ liệu, chúng ta cũng cần biết loại dữ liệu chúng ta đang xử lý.
Dữ liệu có thể được chia thành ba loại chính:
- Số - Chứa các giá trị số. Có thể chia thành hai loại:
- Rời rạc: Các số được tính là "toàn bộ". Ví dụ: Bạn không thể tập 2,5 buổi mà là 2 hoặc 3 buổi
- Liên tục: Các số có thể có độ chính xác vô hạn. Ví dụ: bạn có thể ngủ trong 7 giờ, 30 phút và 20 giây hoặc 7,533 giờ
- Phân loại - Chứa các giá trị không thể đo lường được với nhau. Ví dụ: Màu sắc hoặc loại hình đào tạo
- Thứ tự - Chứa dữ liệu phân loại có thể được đo lường với nhau. Ví dụ: Điểm trường A tốt hơn B, v.v.
Khi biết loại dữ liệu của mình, bạn sẽ có thể biết nên sử dụng kỹ thuật nào khi phân tích chúng.
Loại dữ liệu
Chúng ta có thể sử dụng hàm info() để liệt kê các loại dữ liệu trong tập dữ liệu của mình:
Kết quả:
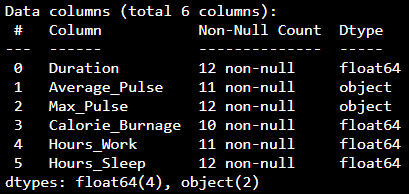
Chúng tôi thấy rằng tập dữ liệu này có hai loại dữ liệu khác nhau:
- Phao64
- Sự vật
Chúng ta không thể sử dụng các đối tượng để tính toán và thực hiện phân tích ở đây. Chúng ta phải chuyển đổi đối tượng kiểu thành float64 (float64 là một số có số thập phân trong Python).
Chúng ta có thể sử dụng hàm astype() để chuyển đổi dữ liệu thành float64.
Ví dụ sau chuyển đổi "Average_Pulse" và "Max_Pulse" thành kiểu dữ liệu float64 (các biến khác đã có kiểu dữ liệu float64):
Ví dụ
health_data["Average_Pulse"]
= health_data['Average_Pulse'].astype(float)
health_data["Max_Pulse"] =
health_data["Max_Pulse"].astype(float)
print
(health_data.info()) Hãy tự mình thử »Kết quả:
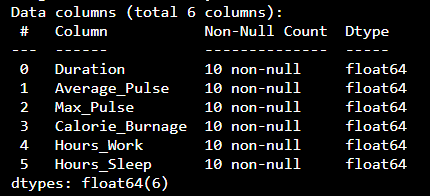
Bây giờ, tập dữ liệu chỉ có kiểu dữ liệu float64.
Phân tích dữ liệu
Khi đã làm sạch tập dữ liệu, chúng ta có thể bắt đầu phân tích dữ liệu.
Chúng ta có thể sử dụng hàm describe() trong Python để tóm tắt dữ liệu:
Kết quả:
| Khoảng thời gian | Trung bình_Pulse | Max_Pulse | Calorie_Đốt cháy | Giờ_Làm việc | Giờ_Ngủ | |
|---|---|---|---|---|---|---|
| Đếm | 10,0 | 10,0 | 10,0 | 10,0 | 10,0 | 10,0 |
| Nghĩa là | 51,0 | 102,5 | 137,0 | 285,0 | 6,6 | 7,5 |
| tiêu chuẩn | 10,49 | 15,4 | 11:35 | 30,28 | 3,63 | 0,53 |
| tối thiểu | 30,0 | 80,0 | 120,0 | 240,0 | 0,0 | 7,0 |
| 25% | 45,0 | 91,25 | 130,0 | 262,5 | 7,0 | 7,0 |
| 50% | 52,5 | 102,5 | 140,0 | 285,0 | 8,0 | 7,5 |
| 75% | 60,0 | 113,75 | 145,0 | 307,5 | 8,0 | 8,0 |
| Tối đa | 60,0 | 125,0 | 150,0 | 330,0 | 10,0 | 8,0 |
- Đếm - Đếm số lượng quan sát
- Mean - Giá trị trung bình
- Std - Độ lệch chuẩn (được giải thích trong chương thống kê)
- Min - Giá trị thấp nhất
- 25% , 50% và 75% là phần trăm (được giải thích trong chương thống kê)
- Max - Giá trị cao nhất
