

Độ phức tạp thời gian DSA
Thời gian chạy
Để hiểu đầy đủ về các thuật toán, chúng ta phải hiểu cách đánh giá thời gian mà thuật toán cần để thực hiện công việc của nó, đó là thời gian chạy.
Khám phá thời gian chạy của thuật toán rất quan trọng vì việc sử dụng thuật toán kém hiệu quả có thể khiến chương trình của chúng tôi bị chậm hoặc thậm chí không thể thực hiện được.
Bằng cách hiểu thời gian chạy thuật toán, chúng tôi có thể chọn thuật toán phù hợp với nhu cầu của mình và chúng tôi có thể làm cho chương trình của mình chạy nhanh hơn và xử lý lượng dữ liệu lớn hơn một cách hiệu quả.
Thời gian chạy thực tế
Khi xem xét thời gian chạy cho các thuật toán khác nhau, chúng tôi sẽ không xem xét thời gian thực tế mà thuật toán được triển khai sử dụng để chạy và đây là lý do.
Nếu chúng ta triển khai một thuật toán bằng ngôn ngữ lập trình và chạy chương trình đó thì thời gian thực tế mà nó sẽ sử dụng phụ thuộc vào nhiều yếu tố:
- ngôn ngữ lập trình được sử dụng để thực hiện thuật toán
- cách lập trình viên viết chương trình cho thuật toán
- trình biên dịch hoặc trình thông dịch được sử dụng để thuật toán được triển khai có thể chạy
- phần cứng trên máy tính mà thuật toán đang chạy
- hệ điều hành và các tác vụ khác đang diễn ra trên máy tính
- lượng dữ liệu mà thuật toán đang xử lý
Với tất cả các yếu tố khác nhau này đóng vai trò trong thời gian chạy thực tế của một thuật toán, làm sao chúng ta có thể biết liệu một thuật toán có nhanh hơn thuật toán khác hay không? Chúng ta cần tìm một thước đo tốt hơn về thời gian chạy.
Độ phức tạp thời gian
Để đánh giá và so sánh các thuật toán khác nhau, thay vì xem xét thời gian chạy thực tế của một thuật toán, sẽ hợp lý hơn khi sử dụng thứ gọi là độ phức tạp về thời gian.
Độ phức tạp về thời gian trừu tượng hơn thời gian chạy thực tế và không xem xét các yếu tố như ngôn ngữ lập trình hoặc phần cứng.
Độ phức tạp về thời gian là số lượng thao tác cần thiết để chạy thuật toán trên lượng lớn dữ liệu. Và số lượng thao tác có thể được coi là thời gian vì máy tính sử dụng một khoảng thời gian cho mỗi thao tác.
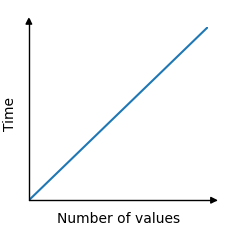
Ví dụ: trong thuật toán tìm giá trị thấp nhất trong mảng , mỗi giá trị trong mảng phải được so sánh một lần. Mỗi so sánh như vậy có thể được coi là một thao tác và mỗi thao tác cần một khoảng thời gian nhất định. Vì vậy tổng thời gian thuật toán cần để tìm giá trị thấp nhất phụ thuộc vào số lượng giá trị trong mảng.
Do đó, thời gian cần thiết để tìm giá trị thấp nhất là tuyến tính với số lượng giá trị. 100 giá trị dẫn đến 100 so sánh và 5000 giá trị dẫn đến 5000 so sánh.
Mối quan hệ giữa thời gian và số lượng giá trị trong mảng là tuyến tính và có thể được hiển thị dưới dạng biểu đồ như sau:
"Một hoạt động"
Khi nói về "các thao tác" ở đây, "một thao tác" có thể mất một hoặc vài chu kỳ CPU và nó thực sự chỉ là một từ giúp chúng ta trừu tượng hóa, để chúng ta có thể hiểu độ phức tạp của thời gian là gì và để chúng ta có thể tìm ra thời gian. độ phức tạp của các thuật toán khác nhau.
Một thao tác trong thuật toán có thể được hiểu là một việc chúng ta thực hiện trong mỗi lần lặp của thuật toán hoặc đối với mỗi phần dữ liệu, cần có thời gian không đổi.
Ví dụ: So sánh hai phần tử mảng và hoán đổi chúng nếu phần tử này lớn hơn phần tử kia, giống như thuật toán Bubble Sort , có thể được hiểu là một thao tác. Việc hiểu đây là một, hai hoặc ba thao tác thực sự không ảnh hưởng đến độ phức tạp về thời gian đối với Sắp xếp nổi bọt vì nó mất thời gian không đổi.
Chúng tôi nói rằng một thao tác mất "thời gian không đổi" nếu nó mất cùng thời gian bất kể lượng dữ liệu (\(n\)) mà thuật toán đang xử lý. Việc so sánh hai phần tử mảng cụ thể và hoán đổi chúng nếu phần tử này lớn hơn phần tử kia, sẽ mất cùng thời gian nếu mảng chứa 10 hoặc 1000 phần tử.
Ký hiệu O lớn
Trong toán học, ký hiệu Big O được sử dụng để mô tả giới hạn trên của hàm số.
Trong khoa học máy tính, ký hiệu Big O được sử dụng cụ thể hơn để tìm độ phức tạp về thời gian trong trường hợp xấu nhất đối với một thuật toán.
Ký hiệu Big O sử dụng chữ cái viết hoa O có dấu ngoặc đơn \(O() \) và bên trong dấu ngoặc đơn có một biểu thức cho biết thời gian chạy thuật toán. Thời gian chạy thường được biểu thị bằng \(n \), là số giá trị trong tập dữ liệu mà thuật toán đang xử lý.
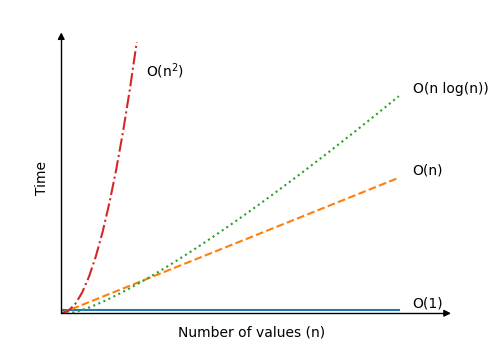
Dưới đây là một số ví dụ về ký hiệu Big O cho các thuật toán khác nhau, chỉ để bạn hình dung:
| Time Complexity | Algorithm |
|---|---|
| \[ O(1) \] |
Looking up a specific element in an array, like this for example:
|
| \[ O(n) \] | Finding the lowest value . The algorithm must do \(n\) operations in an array with \(n\) values to find the lowest value, because the algorithm must compare each value one time. |
| \[ O(n^2) \] |
Bubble sort , Selection sort and Insertion sort are algorithms with this time complexity. The reason for their time complexities are explained on the pages for these algorithms. Large data sets slows down these algorithms significantly. With just an increase in \(n \) from 100 to 200 values, the number of operations can increase by as much as 30000! |
| \[ O(n \log n) \] | The Quicksort algorithm is faster on average than the three sorting algorithms mentioned above, with \(O(n \log n) \) being the average and not the worst case time. Worst case time for Quicksort is also \(O(n^2) \), but it is the average time that makes Quicksort so interesting. We will learn about Quicksort later. |
Đây là thời gian tăng lên khi số lượng giá trị \(n\) tăng đối với các thuật toán khác nhau:
Trường hợp tốt nhất, trung bình và xấu nhất
Độ phức tạp về thời gian của 'trường hợp xấu nhất' đã được đề cập khi giải thích ký hiệu Big O, nhưng làm thế nào một thuật toán có thể có trường hợp xấu nhất?
Thuật toán tìm giá trị thấp nhất trong một mảng có giá trị \(n\) yêu cầu các thao tác \(n\) để thực hiện điều đó và điều đó luôn giống nhau. Vì vậy, thuật toán này có các trường hợp tốt nhất, trung bình và xấu nhất giống nhau.
Nhưng đối với nhiều thuật toán khác, chúng ta sẽ xem xét, nếu chúng ta giữ cố định số lượng giá trị \(n\) thì thời gian chạy vẫn có thể thay đổi nhiều tùy thuộc vào giá trị thực tế.
Không đi sâu vào chi tiết, chúng ta có thể hiểu rằng một thuật toán sắp xếp có thể có thời gian chạy khác nhau, tùy thuộc vào giá trị mà nó sắp xếp.
Chỉ cần tưởng tượng bạn phải sắp xếp 20 giá trị theo cách thủ công từ thấp nhất đến cao nhất:
8, 16, 19, 15, 2, 17, 4, 11, 6, 1, 7, 13, 5, 3, 9, 12, 14, 20, 18, 10Việc này sẽ khiến bạn mất vài giây để hoàn thành.
Bây giờ, hãy tưởng tượng bạn phải sắp xếp 20 giá trị gần như đã được sắp xếp:
1, 2, 3, 4, 5, 20 , 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19Bạn có thể sắp xếp các giá trị rất nhanh, chỉ bằng cách di chuyển 20 đến cuối danh sách là xong, phải không?
Các thuật toán hoạt động tương tự nhau: Đối với cùng một lượng dữ liệu, đôi khi chúng có thể chậm và đôi khi nhanh. Vì vậy, để có thể so sánh độ phức tạp về thời gian của các thuật toán khác nhau, chúng ta thường xem xét trường hợp xấu nhất bằng cách sử dụng ký hiệu Big O.
Big O được giải thích bằng toán học
Tùy thuộc vào nền tảng Toán học của bạn, phần này có thể khó hiểu. Nó nhằm tạo ra một cơ sở toán học vững chắc hơn cho những ai cần Big O được giải thích kỹ lưỡng hơn.
Nếu bây giờ bạn chưa hiểu điều này, đừng lo lắng, bạn có thể quay lại sau. Và nếu phép toán ở đây vượt quá khả năng của bạn, đừng quá lo lắng về điều đó, bạn vẫn có thể tận hưởng các thuật toán khác nhau trong hướng dẫn này, tìm hiểu cách lập trình chúng và hiểu chúng nhanh hay chậm.
Trong Toán học, ký hiệu Big O được sử dụng để tạo giới hạn trên cho một hàm và trong Khoa học Máy tính, ký hiệu Big O được sử dụng để mô tả thời gian chạy của thuật toán tăng như thế nào khi số lượng giá trị dữ liệu \(n\) tăng lên.
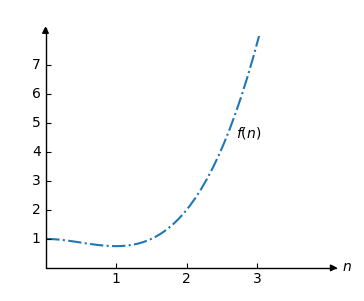
Ví dụ, hãy xem xét hàm:
\[f(n) = 0,5n^3 -0,75n^2+1 \]
Đồ thị của hàm \(f\) trông như thế này:
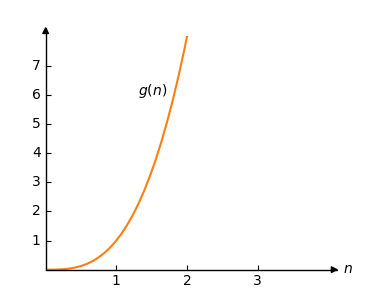
Hãy xem xét một chức năng khác:
\[g(n) = n^3 \]
Mà chúng ta có thể vẽ như thế này:
Sử dụng ký hiệu Big O, chúng ta có thể nói rằng \(O(g(n))\) là giới hạn trên của \(f(n)\) vì chúng ta có thể chọn một hằng số \(C\) sao cho \(C \cdot g(n)>f(n)\) miễn là \(n\) đủ lớn.
Được rồi, hãy thử. Chúng ta chọn \(C=0,75\) sao cho \(C \cdot g(n) = 0,75 \cdot n^3\).
Bây giờ hãy vẽ \(0.75 \cdot g(n)\) và \(f(n)\) trong cùng một ô:
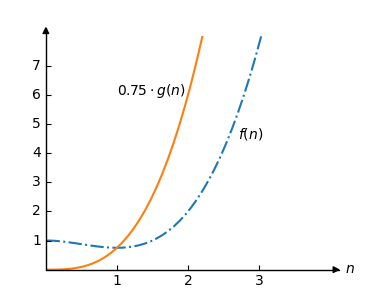
Chúng ta có thể thấy rằng \(O(g(n))=O(n^3)\) là giới hạn trên của \(f(n)\) vì \(0.75 \cdot g(n) > f(n) \) với mọi \(n\) lớn hơn 1.
Trong ví dụ trên \(n\) phải lớn hơn 1 để \(O(n^3)\) là giới hạn trên. Chúng tôi gọi giới hạn này là \(n_0\).
Sự định nghĩa
Đặt \(f(n)\) và \(g(n)\) là hai hàm. Chúng ta nói rằng \(f(n)\) là \(O(g(n))\) khi và chỉ khi có các hằng số dương \(C\) và \(n_0\) sao cho
\[ C \cdot g(n) > f(n) \]
cho tất cả \(n>n_0\).
Khi đánh giá độ phức tạp về thời gian cho một thuật toán, \(O()\) chỉ đúng với một số lượng lớn các giá trị \(n\), vì đó là lúc độ phức tạp về thời gian trở nên quan trọng. Nói cách khác: nếu chúng ta sắp xếp 10, 20 hoặc 100 giá trị, thì độ phức tạp về thời gian của thuật toán sẽ không thú vị lắm, vì dù sao thì máy tính cũng sẽ sắp xếp các giá trị trong một thời gian ngắn.
