

Học máy - Đường cong AUC - ROC
Trên trang này, W3schools.com hợp tác với Học viện Khoa học Dữ liệu NYC để cung cấp nội dung đào tạo kỹ thuật số cho sinh viên của chúng tôi.
Đường cong AUC - ROC
Trong phân loại có nhiều thước đo đánh giá khác nhau. Phổ biến nhất là độ chính xác , đo lường mức độ thường xuyên đúng của mô hình. Đây là một thước đo tuyệt vời vì nó dễ hiểu và thường mang lại những dự đoán chính xác nhất. Có một số trường hợp bạn có thể cân nhắc sử dụng số liệu đánh giá khác.
Một số liệu phổ biến khác là AUC , diện tích dưới đường cong đặc tính vận hành máy thu ( ROC ). Đường cong đặc tính hoạt động của Máy thu biểu thị tỷ lệ dương tính thật ( TP ) so với tỷ lệ dương tính giả ( FP ) ở các ngưỡng phân loại khác nhau. Các ngưỡng là các ngưỡng xác suất khác nhau để phân tách hai lớp trong phân loại nhị phân. Nó sử dụng xác suất để cho chúng ta biết mô hình phân tách các lớp tốt đến mức nào.
Dữ liệu mất cân bằng
Giả sử chúng ta có một tập dữ liệu không cân bằng trong đó phần lớn dữ liệu của chúng ta có một giá trị. Chúng ta có thể đạt được độ chính xác cao cho mô hình bằng cách dự đoán lớp đa số.
Ví dụ
import numpy as np
from sklearn.metrics import accuracy_score, confusion_matrix, roc_auc_score, roc_curve
n = 10000
ratio = .95
n_0 = int((1-ratio) * n)
n_1 = int(ratio * n)
y = np.array([0] * n_0 + [1] * n_1)
# below are the probabilities obtained from a hypothetical model that always predicts the majority class
# probability of predicting class 1 is going to be 100%
y_proba = np.array([1]*n)
y_pred = y_proba > .5
print(f'accuracy score: {accuracy_score(y, y_pred)}')
cf_mat = confusion_matrix(y, y_pred)
print('Confusion matrix')
print(cf_mat)
print(f'class 0 accuracy: {cf_mat[0][0]/n_0}')
print(f'class 1 accuracy: {cf_mat[1][1]/n_1}')
Chạy ví dụ »QUẢNG CÁO
Mặc dù chúng tôi đạt được độ chính xác rất cao nhưng mô hình không cung cấp thông tin về dữ liệu nên không hữu ích. Chúng tôi dự đoán chính xác lớp 1 100% trong khi dự đoán không chính xác lớp 0 0% thời gian. Tuy nhiên, có thể sẽ tốt hơn nếu có một mô hình có thể tách biệt hai lớp một cách nào đó.
Ví dụ
# below are the probabilities obtained from a hypothetical model that doesn't always predict the mode
y_proba_2 = np.array(
np.random.uniform(0, .7, n_0).tolist() +
np.random.uniform(.3, 1, n_1).tolist()
)
y_pred_2 = y_proba_2 > .5
print(f'accuracy score: {accuracy_score(y, y_pred_2)}')
cf_mat = confusion_matrix(y, y_pred_2)
print('Confusion matrix')
print(cf_mat)
print(f'class 0 accuracy: {cf_mat[0][0]/n_0}')
print(f'class 1 accuracy: {cf_mat[1][1]/n_1}') Chạy ví dụ »Đối với nhóm dự đoán thứ hai, chúng tôi không có điểm chính xác cao như nhóm đầu tiên nhưng độ chính xác cho từng lớp cân bằng hơn. Sử dụng độ chính xác làm thước đo đánh giá, chúng tôi sẽ xếp hạng mô hình đầu tiên cao hơn mô hình thứ hai mặc dù nó không cho chúng tôi biết bất kỳ điều gì về dữ liệu.
Trong những trường hợp như thế này, việc sử dụng số liệu đánh giá khác như AUC sẽ được ưu tiên hơn.
import matplotlib.pyplot as plt
def plot_roc_curve(true_y, y_prob):
"""
plots the roc curve based of the probabilities
"""
fpr, tpr, thresholds = roc_curve(true_y, y_prob)
plt.plot(fpr, tpr)
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
Ví dụ
Mô hình 1:
plot_roc_curve(y, y_proba)
print(f'model 1 AUC score: {roc_auc_score(y, y_proba)}')
Kết quả
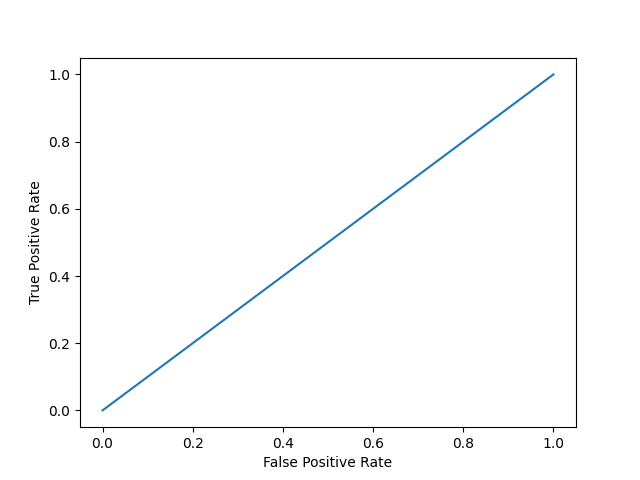
Điểm AUC của mô hình 1: 0,5
Ví dụ
Mô hình 2:
plot_roc_curve(y, y_proba_2)
print(f'model 2 AUC score: {roc_auc_score(y, y_proba_2)}')
Kết quả

Điểm AUC của mô hình 2: 0,8270551578947367
Điểm AUC khoảng 0,5 có nghĩa là mô hình không thể phân biệt giữa hai lớp và đường cong sẽ trông giống như một đường có độ dốc bằng 1. Điểm AUC gần hơn 1 có nghĩa là mô hình có khả năng tách hai lớp và đường cong sẽ đến gần góc trên bên trái của biểu đồ.
Xác suất
Vì AUC là số liệu sử dụng xác suất của các dự đoán về lớp nên chúng tôi có thể tự tin hơn vào mô hình có điểm AUC cao hơn mô hình có điểm thấp hơn ngay cả khi chúng có độ chính xác tương tự.
Trong dữ liệu bên dưới, chúng ta có hai bộ xác suất từ các mô hình giả định. Loại đầu tiên có xác suất không được "tự tin" bằng khi dự đoán hai lớp (xác suất gần bằng 0,5). Loại thứ hai có xác suất “tự tin” hơn khi dự đoán hai lớp (xác suất gần với các cực trị 0 hoặc 1).
Ví dụ
import numpy as np
n = 10000
y = np.array([0] * n + [1] * n)
#
y_prob_1 = np.array(
np.random.uniform(.25, .5, n//2).tolist() +
np.random.uniform(.3, .7, n).tolist() +
np.random.uniform(.5, .75, n//2).tolist()
)
y_prob_2 = np.array(
np.random.uniform(0, .4, n//2).tolist() +
np.random.uniform(.3, .7, n).tolist() +
np.random.uniform(.6, 1, n//2).tolist()
)
print(f'model 1 accuracy score: {accuracy_score(y, y_prob_1>.5)}')
print(f'model 2 accuracy score: {accuracy_score(y, y_prob_2>.5)}')
print(f'model 1 AUC score: {roc_auc_score(y, y_prob_1)}')
print(f'model 2 AUC score: {roc_auc_score(y, y_prob_2)}') Chạy ví dụ »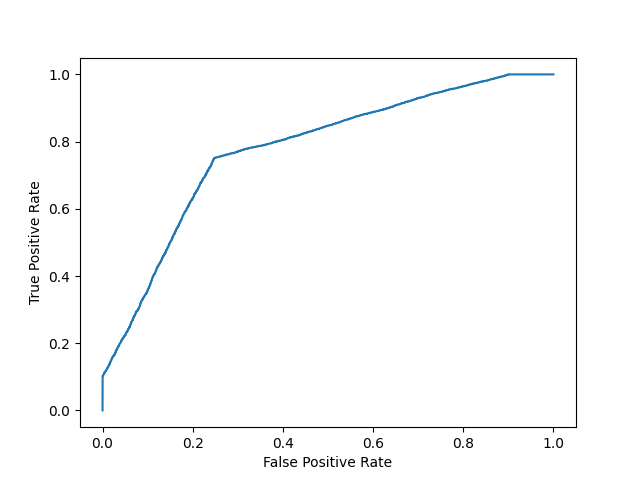
Ví dụ
Mô hình lô 2:
fpr, tpr, thresholds = roc_curve(y, y_prob_2)
plt.plot(fpr, tpr)Kết quả

Mặc dù độ chính xác của hai mô hình là tương tự nhau, nhưng mô hình có điểm AUC cao hơn sẽ đáng tin cậy hơn vì nó tính đến xác suất dự đoán. Nó có nhiều khả năng mang lại cho bạn độ chính xác cao hơn khi dự đoán dữ liệu trong tương lai.
