

Học máy - Hàng xóm gần nhất K (KNN)
Trên trang này, W3schools.com hợp tác với Học viện Khoa học Dữ liệu NYC để cung cấp nội dung đào tạo kỹ thuật số cho sinh viên của chúng tôi.
KNN
KNN là một thuật toán học máy (ML) đơn giản, có giám sát, có thể được sử dụng cho các tác vụ phân loại hoặc hồi quy - và cũng thường được sử dụng trong việc quy định giá trị bị thiếu. Nó dựa trên ý tưởng rằng các quan sát gần nhất với một điểm dữ liệu nhất định là những quan sát "tương tự" nhất trong tập dữ liệu và do đó chúng ta có thể phân loại các điểm không lường trước được dựa trên giá trị của các điểm hiện có gần nhất. Bằng cách chọn K , người dùng có thể chọn số lượng quan sát lân cận để sử dụng trong thuật toán.
Ở đây, chúng tôi sẽ chỉ cho bạn cách triển khai thuật toán KNN để phân loại và cho biết các giá trị khác nhau của K ảnh hưởng đến kết quả như thế nào.
Làm thế nào nó hoạt động?
K là số hàng xóm gần nhất để sử dụng. Để phân loại, đa số phiếu bầu được sử dụng để xác định xem quan sát mới sẽ thuộc loại nào. Các giá trị K lớn hơn thường mạnh hơn đối với các ngoại lệ và tạo ra ranh giới quyết định ổn định hơn các giá trị rất nhỏ ( K=3 sẽ tốt hơn K=1 , điều này có thể tạo ra kết quả không mong muốn.
Ví dụ
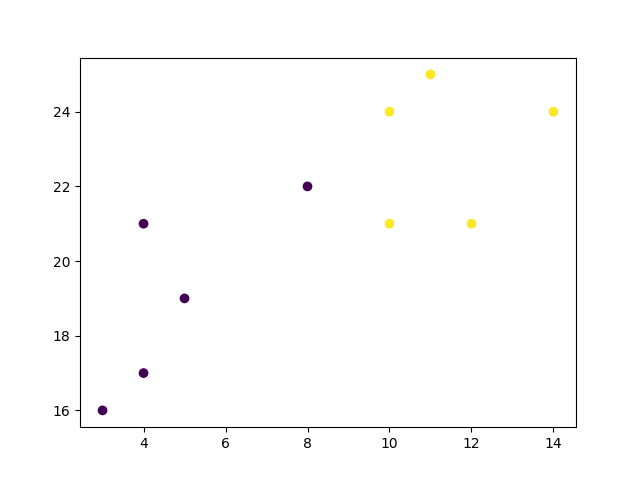
Bắt đầu bằng cách trực quan hóa một số điểm dữ liệu:
import matplotlib.pyplot as plt
x = [4, 5, 10, 4, 3, 11, 14 , 8, 10, 12]
y = [21, 19, 24, 17, 16, 25, 24, 22, 21, 21]
classes = [0, 0, 1, 0, 0, 1, 1, 0, 1, 1]
plt.scatter(x, y, c=classes)
plt.show()Kết quả
QUẢNG CÁO
Bây giờ chúng tôi điều chỉnh thuật toán KNN với K=1:
from sklearn.neighbors import KNeighborsClassifier
data = list(zip(x, y))
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(data, classes)
Và sử dụng nó để phân loại một điểm dữ liệu mới:
Ví dụ
new_x = 8
new_y = 21
new_point = [(new_x, new_y)]
prediction = knn.predict(new_point)
plt.scatter(x + [new_x], y + [new_y], c=classes + [prediction[0]])
plt.text(x=new_x-1.7, y=new_y-0.7, s=f"new point, class: {prediction[0]}")
plt.show()
Kết quả

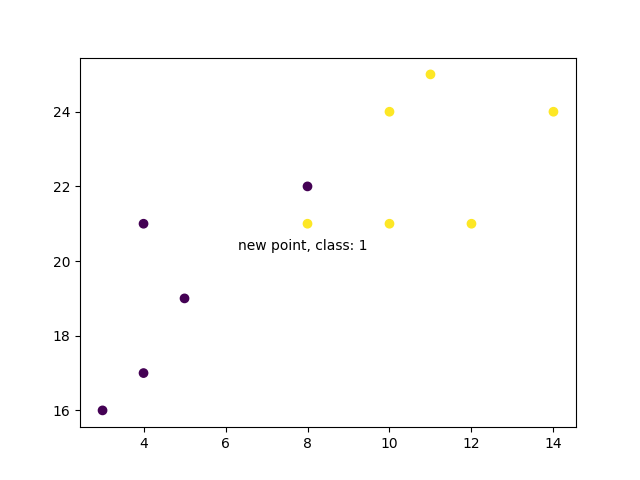
Bây giờ chúng tôi làm điều tương tự, nhưng với giá trị K cao hơn sẽ thay đổi dự đoán:
Ví dụ
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(data, classes)
prediction = knn.predict(new_point)
plt.scatter(x + [new_x], y + [new_y], c=classes + [prediction[0]])
plt.text(x=new_x-1.7, y=new_y-0.7, s=f"new point, class: {prediction[0]}")
plt.show()Kết quả
Ví dụ giải thích
Nhập các mô-đun bạn cần.
Bạn có thể tìm hiểu về mô-đun Matplotlib trong "Hướng dẫn Matplotlib của chúng tôi.
scikit-learn là một thư viện phổ biến để học máy bằng Python.
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
Tạo các mảng giống với các biến trong tập dữ liệu. Chúng tôi có hai tính năng đầu vào ( x và y ) và sau đó là lớp mục tiêu ( class ). Các tính năng đầu vào được gắn nhãn trước với lớp mục tiêu của chúng tôi sẽ được sử dụng để dự đoán lớp dữ liệu mới. Lưu ý rằng mặc dù chúng tôi chỉ sử dụng hai tính năng đầu vào ở đây, nhưng phương thức này sẽ hoạt động với bất kỳ số lượng biến nào:
x = [4, 5, 10, 4, 3, 11, 14 , 8, 10, 12]
y = [21, 19, 24, 17, 16, 25, 24, 22, 21, 21]
classes = [0, 0, 1, 0, 0, 1, 1, 0, 1, 1]
Biến các tính năng đầu vào thành một tập hợp các điểm:
data = list(zip(x, y))
print(data)
Kết quả:
[(4, 21), (5, 19), (10, 24), (4, 17), (3, 16), (11, 25), (14, 24), (8, 22), (10, 21), (12, 21)]
Sử dụng các tính năng đầu vào và lớp mục tiêu, chúng tôi điều chỉnh mô hình KNN trên mô hình bằng cách sử dụng 1 lân cận gần nhất:
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(data, classes)
Sau đó, chúng ta có thể sử dụng cùng một đối tượng KNN để dự đoán lớp điểm dữ liệu mới, không lường trước được. Đầu tiên, chúng ta tạo các tính năng x và y mới, sau đó gọi knn.predict() trên điểm dữ liệu mới để nhận lớp 0 hoặc 1:
new_x = 8
new_y = 21
new_point = [(new_x, new_y)]
prediction = knn.predict(new_point)
print(prediction)
Kết quả:
[0]
Khi chúng ta vẽ biểu đồ tất cả dữ liệu cùng với điểm và lớp mới, chúng ta có thể thấy nó được gắn nhãn màu xanh lam với lớp 1 . Chú thích văn bản chỉ nhằm làm nổi bật vị trí của điểm mới:
plt.scatter(x + [new_x], y + [new_y], c=classes + [prediction[0]])
plt.text(x=new_x-1.7, y=new_y-0.7, s=f"new point, class: {prediction[0]}")
plt.show()
Kết quả:
Tuy nhiên, khi chúng ta thay đổi số lượng hàng xóm thành 5, số điểm được sử dụng để phân loại điểm mới của chúng ta sẽ thay đổi. Kết quả là, việc phân loại điểm mới cũng vậy:
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(data, classes)
prediction = knn.predict(new_point)
print(prediction)
Kết quả:
[1]
Khi vẽ biểu đồ lớp của điểm mới cùng với các điểm cũ hơn, chúng tôi lưu ý rằng màu sắc đã thay đổi dựa trên nhãn lớp liên quan:
plt.scatter(x + [new_x], y + [new_y], c=classes + [prediction[0]])
plt.text(x=new_x-1.7, y=new_y-0.7, s=f"new point, class: {prediction[0]}")
plt.show()
Kết quả:
