

Học máy - Cây quyết định

Cây quyết định
Trong chương này chúng tôi sẽ hướng dẫn bạn cách tạo "Cây quyết định". Cây quyết định là một sơ đồ luồng và có thể giúp bạn đưa ra quyết định dựa trên kinh nghiệm trước đó.
Trong ví dụ này, một người sẽ cố gắng quyết định xem mình có nên đi xem một chương trình hài kịch hay không.
May mắn thay, người mẫu của chúng tôi đã đăng ký mỗi khi có một buổi biểu diễn hài kịch trong thị trấn và đăng ký một số thông tin về diễn viên hài, đồng thời đăng ký xem anh ấy/cô ấy có đi hay không.
| Tuổi | Kinh nghiệm | Thứ hạng | Quốc tịch | Đi |
| 36 | 10 | 9 | Vương quốc Anh | KHÔNG |
| 42 | 12 | 4 | Hoa Kỳ | KHÔNG |
| 23 | 4 | 6 | N | KHÔNG |
| 52 | 4 | 4 | Hoa Kỳ | KHÔNG |
| 43 | 21 | số 8 | Hoa Kỳ | ĐÚNG |
| 44 | 14 | 5 | Vương quốc Anh | KHÔNG |
| 66 | 3 | 7 | N | ĐÚNG |
| 35 | 14 | 9 | Vương quốc Anh | ĐÚNG |
| 52 | 13 | 7 | N | ĐÚNG |
| 35 | 5 | 9 | N | ĐÚNG |
| 24 | 3 | 5 | Hoa Kỳ | KHÔNG |
| 18 | 3 | 7 | Vương quốc Anh | ĐÚNG |
| 45 | 9 | 9 | Vương quốc Anh | ĐÚNG |
Giờ đây, dựa trên tập dữ liệu này, Python có thể tạo một cây quyết định có thể được sử dụng để quyết định xem có chương trình mới nào đáng tham dự hay không.
Làm thế nào nó hoạt động?
Đầu tiên, đọc tập dữ liệu với gấu trúc:
Để tạo cây quyết định, tất cả dữ liệu phải ở dạng số.
Chúng ta phải chuyển đổi các cột không phải số 'Quốc tịch' và 'Đi' thành các giá trị số.
Pandas có phương thức map() lấy từ điển có thông tin về cách chuyển đổi các giá trị.
{'UK': 0, 'USA': 1, 'N': 2}
Có nghĩa là chuyển đổi các giá trị 'UK' thành 0, 'USA' thành 1 và 'N' thành 2.
Ví dụ
Thay đổi giá trị chuỗi thành giá trị số:
d = {'UK': 0,
'USA': 1, 'N': 2}
df['Nationality'] = df['Nationality'].map(d)
d =
{'YES': 1, 'NO': 0}
df['Go'] = df['Go'].map(d)
print(df)Sau đó, chúng ta phải tách các cột tính năng khỏi cột mục tiêu .
Các cột tính năng là các cột mà chúng tôi cố gắng dự đoán từ đó và cột mục tiêu là cột có các giá trị mà chúng tôi cố gắng dự đoán.
Ví dụ
X là cột tính năng, y là cột mục tiêu:
features = ['Age', 'Experience', 'Rank', 'Nationality']
X = df[features]
y = df['Go']
print(X)
print(y)Bây giờ chúng ta có thể tạo cây quyết định thực tế, điều chỉnh nó phù hợp với các chi tiết của chúng ta. Bắt đầu bằng cách nhập các mô-đun chúng tôi cần:
Ví dụ
Tạo và hiển thị Cây quyết định:
import pandas
from sklearn import tree
from sklearn.tree import
DecisionTreeClassifier
import matplotlib.pyplot as plt
df =
pandas.read_csv("data.csv")
d = {'UK': 0, 'USA': 1, 'N': 2}
df['Nationality']
= df['Nationality'].map(d)
d = {'YES': 1, 'NO': 0}
df['Go'] = df['Go'].map(d)
features = ['Age', 'Experience', 'Rank', 'Nationality']
X = df[features]
y = df['Go']
dtree = DecisionTreeClassifier()
dtree = dtree.fit(X,
y)
tree.plot_tree(dtree, feature_names=features)Kết quả được giải thích
Cây quyết định sử dụng các quyết định trước đó của bạn để tính toán khả năng bạn có muốn đi xem diễn viên hài hay không.
Chúng ta hãy đọc các khía cạnh khác nhau của cây quyết định:

Thứ hạng
Rank <= 6.5 nghĩa là mọi diễn viên hài có hạng từ 6,5 trở xuống sẽ đi theo mũi tên True (ở bên trái), còn lại sẽ đi theo Mũi tên False (ở bên phải).
gini = 0.497 đề cập đến chất lượng của phần phân tách và luôn là một số nằm trong khoảng từ 0,0 đến 0,5, trong đó 0,0 có nghĩa là tất cả các mẫu đều có cùng kết quả và 0,5 có nghĩa là việc phân chia được thực hiện chính xác ở giữa.
samples = 13 có nghĩa là đến thời điểm này còn lại 13 diễn viên hài trong quyết định, đó là tất cả vì đây là bước đầu tiên.
value = [6, 7] nghĩa là trong số 13 nghệ sĩ hài này, 6 người sẽ nhận được "KHÔNG" và 7 người sẽ nhận được "ĐI".
Gini
Có nhiều cách để chia mẫu, chúng tôi sử dụng phương pháp GINI trong hướng dẫn này.
Phương pháp Gini sử dụng công thức này:
Gini = 1 - (x/n) 2 - (y/n) 2
Trong đó x là số câu trả lời tích cực ("GO"), n là số lượng mẫu và y là số câu trả lời phủ định ("NO"), cho chúng ta phép tính này:
1 - (7 / 13) 2 - (6 / 13) 2 = 0.497

Bước tiếp theo có hai hộp, một hộp dành cho các diễn viên hài có 'Xếp hạng' từ 6,5 trở xuống và một hộp dành cho những người còn lại.
Đúng - 5 diễn viên hài kết thúc ở đây:
gini = 0.0 có nghĩa là tất cả các mẫu đều có kết quả như nhau.
samples = 5 nghĩa là còn lại 5 diễn viên hài trong nhánh này (5 diễn viên hài có Rank từ 6,5 trở xuống).
value = [5, 0] có nghĩa là 5 sẽ nhận được "KHÔNG" và 0 sẽ nhận được "ĐI".
Sai - 8 diễn viên hài tiếp tục:
Quốc tịch
Nationality <= 0.5 có nghĩa là các diễn viên hài có giá trị quốc tịch nhỏ hơn 0,5 sẽ đi theo mũi tên bên trái (có nghĩa là tất cả mọi người đến từ Vương quốc Anh, ), và những người còn lại sẽ đi theo mũi tên bên phải.
gini = 0.219 có nghĩa là khoảng 22% số mẫu sẽ đi theo một hướng.
samples = 8 nghĩa là còn lại 8 diễn viên hài trong nhánh này (8 diễn viên hài có Rank cao hơn 6,5).
value = [1, 7] nghĩa là trong 8 diễn viên hài này, 1 người sẽ nhận được "KHÔNG" và 7 người sẽ nhận được "ĐI".
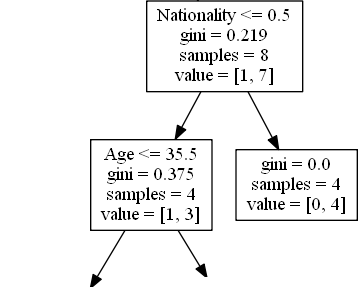
Đúng - 4 diễn viên hài tiếp tục:
Tuổi
Age <= 35.5 có nghĩa là các diễn viên hài ở độ tuổi 35,5 trở xuống sẽ đi theo mũi tên sang trái, còn lại sẽ đi theo mũi tên sang phải.
gini = 0.375 có nghĩa là khoảng 37,5% số mẫu sẽ đi theo một hướng.
samples = 4 nghĩa là còn lại 4 nghệ sĩ hài ở nhánh này (4 nghệ sĩ hài đến từ Anh).
value = [1, 3] nghĩa là trong 4 diễn viên hài này, 1 người sẽ nhận được "KHÔNG" và 3 người sẽ nhận được "ĐI".
Sai - 4 diễn viên hài kết thúc ở đây:
gini = 0.0 có nghĩa là tất cả các mẫu đều có kết quả như nhau.
samples = 4 nghĩa là còn lại 4 diễn viên hài ở nhánh này (4 diễn viên hài không đến từ Vương quốc Anh).
value = [0, 4] nghĩa là trong 4 diễn viên hài này, 0 sẽ nhận điểm "KHÔNG" và 4 sẽ nhận điểm "ĐI".

Đúng - 2 Diễn Viên Hài Kết Thúc Tại Đây:
gini = 0.0 có nghĩa là tất cả các mẫu đều có kết quả như nhau.
samples = 2 nghĩa là nhánh này còn lại 2 diễn viên hài (2 diễn viên hài ở độ tuổi 35,5 trở xuống).
value = [0, 2] nghĩa là trong 2 diễn viên hài này, 0 sẽ nhận điểm "KHÔNG" và 2 sẽ nhận điểm "ĐI".
Sai - 2 diễn viên hài tiếp tục:
Kinh nghiệm
Experience <= 9.5 có nghĩa là diễn viên hài có 9,5 năm kinh nghiệm trở xuống sẽ đi theo mũi tên sang trái, còn lại sẽ đi theo mũi tên sang phải.
gini = 0.5 có nghĩa là 50% số mẫu sẽ đi theo một hướng.
samples = 2 nghĩa là nhánh này còn lại 2 diễn viên hài (2 diễn viên hài lớn hơn 35,5 tuổi).
value = [1, 1] nghĩa là trong 2 diễn viên hài này, 1 người sẽ nhận được "KHÔNG" và 1 người sẽ nhận được "ĐI".

Đúng - 1 Diễn Viên Hài Kết Thúc Tại Đây:
gini = 0.0 có nghĩa là tất cả các mẫu đều có kết quả như nhau.
samples = 1 nghĩa là ngành này còn lại 1 diễn viên hài (1 diễn viên hài có 9,5 năm kinh nghiệm trở xuống).
value = [0, 1] có nghĩa là 0 sẽ nhận được "KHÔNG" và 1 sẽ nhận được "ĐI".
Sai - 1 diễn viên hài kết thúc ở đây:
gini = 0.0 có nghĩa là tất cả các mẫu đều có kết quả như nhau.
samples = 1 nghĩa là ngành này còn lại 1 diễn viên hài (1 diễn viên hài có trên 9,5 năm kinh nghiệm).
value = [1, 0] có nghĩa là 1 sẽ nhận được "KHÔNG" và 0 sẽ nhận được "ĐI".
Dự đoán giá trị
Chúng ta có thể sử dụng Cây quyết định để dự đoán các giá trị mới.
Ví dụ: Tôi có nên đi xem một chương trình có sự tham gia của một diễn viên hài người Mỹ 40 tuổi, có 10 năm kinh nghiệm và xếp hạng hài kịch là 7 không?
Ví dụ
Sử dụng phương thức dự đoán() để dự đoán các giá trị mới:
print(dtree.predict([[40, 10, 7, 1]]))Ví dụ
Câu trả lời sẽ là gì nếu xếp hạng hài kịch là 6?
print(dtree.predict([[40, 10, 6, 1]]))Kết quả khác nhau
Bạn sẽ thấy rằng Cây Quyết định mang lại cho bạn các kết quả khác nhau nếu bạn chạy nó đủ số lần, ngay cả khi bạn cung cấp cho nó cùng một dữ liệu.
Đó là vì Cây quyết định không cho chúng ta câu trả lời chắc chắn 100%. Nó dựa trên xác suất của một kết quả và câu trả lời sẽ khác nhau.
